select ~~ from ~~;
-- select 뒤에는 테이블에서 가져올 컬럼명을 적는다
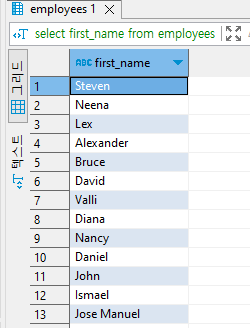
select first_name
-- from 뒤에는 데이터를 가져올 테이블 명을 적는다
-- 실행할 SQL 마지막에는 세미콜론을 적는다.
from employees;
select *
-- 모든 컬럼을 가져올 때에는 *을 적는다.
select *
from employees;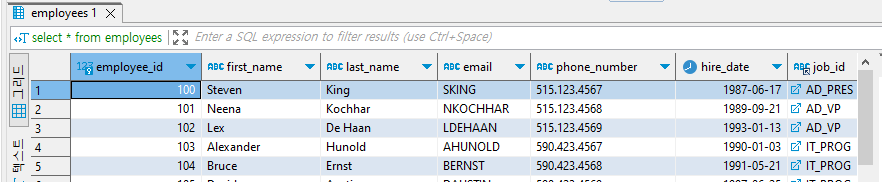
where
select *
from employees
-- where은 데이터를 조건에 맞는 것만 가져오도록 제한한다
where employee_id < 105;
employees 테이블에서 last_name이 King인 사람 조회하기
select *
from employees
-- 컬럼명 띄어쓰기 할 때 언더바를 사용
-- 문자열은 홑따옴표를 사용
-- 같다라는 코드가 (=) 하나다 (프로그래밍 언어와 다름)
where last_name = 'King';
and, or
-- 조건을 연결 할 때에는 and, or을 사용한다.
select *
from employees
where last_name = 'King'
-- 조건을 연결 할 때에는 and, or을 사용한다.
-- 여러 조건을 사용 할 때는 나뉘어지는 방식을 잘 생각한다
-- 묶여야 될 곳은 소괄호로 묶는다
and (employee_id = 100
or employee_id = 101);
괄호 주의
select *
from employees
where last_name = 'King'
-- 조건을 연결 할 때에는 and, or을 사용한다.
-- 여러 조건을 사용 할 때는 나뉘어지는 방식을 잘 생각한다
-- 묶여야 될 곳은 소괄호로 묶는다
and employee_id = 100
or employee_id = 101;
group by
-- group by 특정 컬럼을 기준으로 그룹을 만들 때 사용한다
select *
from employees
-- group by 특정 컬럼을 기준으로 그룹을 만들 때 사용한다
group by job_id;
group by
having
-- group by를 사용하면 having과 select에서 그룹함수를 사용할 수 있다
-- group by없이도 select에서 그룹함수 일부를 사용할 수 있다
-- having은 그룹을 기준으로 그룹함수 또는 컬럼을 이용해서 조건 검색
-- group by를 사용하면 having과 select에서 그룹함수를 사용할 수 있다
-- 컬럼 위치에 수학 계산도 가능하다
-- as는 컬럼의 별명을 만들 수 있다
select job_id, sum(salary), count(salary), sum(salary)/count(salary) as 평균연봉
from employees
group by job_id
-- having은 그룹을 기준으로 그룹함수 또는 컬럼을 이용해서 조건 검색
having sum(salary) > 40000;
order by
-- order by 데이터를 특정 컬럼 기준으로 정렬할 때 사용한다
-- 오름차순 asc / 내림차순 desc
select *
from employees
-- order by 데이터를 특정 컬럼 기준으로 정렬할 때 사용한다
-- 오름차순 asc / 내림차순 desc
order by salary desc;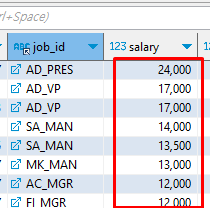
like
-- 문자열의 일부내용을 생략할 때에는 %를 사용한다
-- 문자열 일부 내용 검색 시에는 = 보다는 like를 사용한다
select *
from employees
-- 문자열의 일부내용을 생략할 때에는 %를 사용한다
-- 문자열 일부 내용 검색 시에는 = 보다는 like를 사용한다
where first_name like 'j%';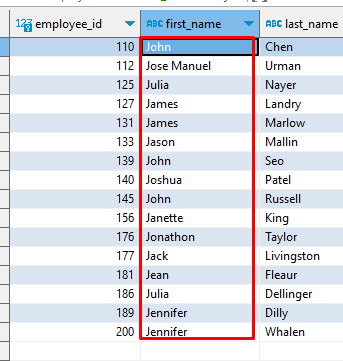
is null
-- employees에서 커미션이 없는 사람만 찾기
-- null 조건은 =이나 like가 아니라 is를 사용한다
is null / is not null
-- employees에서 커미션이 없는 사람만 찾기
select *
from employees
-- null 조건은 =이나 like가 아니라 is를 사용한다
where commission_pct is null;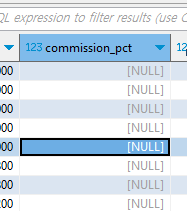
distinct
-- distinct는 select에서 컬럼의 중복을 제거한다
-- distinct는 select에서 컬럼의 중복을 제거한다
select distinct department_id
from employees;
concat
-- concat은 문자열을 더한다
-- 직원들 first_name과 이메일을 뽑아줘
-- concat은 문자열을 더한다
select first_name,email, concat(email, '@test.com')
from employees;
between
-- 1999-01-01 ~ 1999-12-31사이에 입사한 사람
-- between을 사용하면 a이상 b이하의 범위 검색이 가능하다
-- 1999-01-01 ~ 1999-12-31사이에 입사한 사람
select *
from employees
-- between을 사용하면 a이상 b이하의 범위 검색이 가능하다
where hire_date between '1999-01-01' and '1999-12-31'
in
-- job_id가 IT_PROG, FI_ACCOUNT인 사원 정보 조회
두개가 똑같이 검색된다
-- job_id가 IT_PROG, FI_ACCOUNT인 사원 정보 조회
select *
from employees
where job_id = 'IT_PROG'
or job_id = 'FI_ACCOUNT';
select *
from employees
where job_id in ('IT_PROG', 'FI_ACCOUNT');
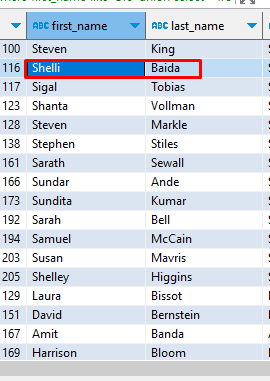
union, union all
-- 두가지 결과를 합치고싶다
union all -- 값이 중복가능하다
-- 두가지 결과를 합치고싶다
-- first_name이 S로 시작하는 사원
select *
from employees
where first_name like 'S%'
union all -- 값이 중복가능하다
-- last_name이 B로 시작하는 사원
select *
from employees
where last_name like 'B%';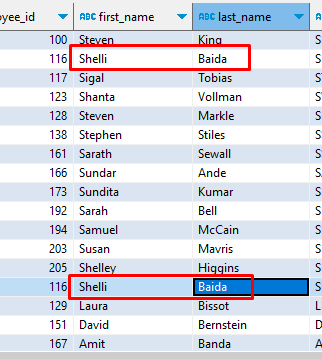
select if
-- 커미션이 null이면 0으로 바꾸고 싶다
-- if(조건, 참결과, 거짓결과)
-- 커미션이 null이면 0으로 바꾸고 싶다
-- if(조건, 참결과, 거짓결과)
select first_name, if(commission_pct is null, 0 , commission_pct)
from employees
'백엔드 > DB' 카테고리의 다른 글
| [MariaDB] MariaDB 학습 - SQL문 - 문자 함수 (0) | 2023.07.07 |
|---|---|
| [MariaDB] MariaDB 학습 - 실습 문제 (0) | 2023.07.07 |
| [MariaDB] MariaDB 학습 - 데이터 넣기 (0) | 2023.07.07 |
| [MariaDB] DBeaver 세팅 (0) | 2023.07.07 |
| [MariaDB] MariaDB, DBeaver 설치 (0) | 2023.07.07 |